 이 누리집은
대한민국 공식 전자정부 누리집입니다.
이 누리집은
대한민국 공식 전자정부 누리집입니다.
점검 중
<모두의 말뭉치>
일부 기능 장애로 인하여 해당 신청이 불가능합니다.
최대한 빠르게 복구할 수 있도록 노력하겠습니다.
* 시스템 이용 장애 문의: 051-927-7111
※ 이 과제는 2024년 HCLT '인공지능(AI)말평' 활용 연구 우수 논문 선정을 위해 활용되었음
과제 개요
‘표의 일부분에 대한 해석 생성’은 자료로부터 텍스트를 생성하는 과제 중 하나로, 주어진 표의 특정 부분을 설명하는 문장을 만드는 과제이다. 위키피디아(Wikipedia) 등 다양한 웹 문서 내에서 핵심적인 정보는 표 형식으로 기술되어 있는 경우가 많다. 이러한 데이터를 인공지능이 잘 이해하기 위해서는 인공지능 언어 처리 기술을 통해 표의 내용을 잘 요약하고 설명할 수 있는지 평가할 필요가 있다.
‘표의 일부분에 대한 해석 생성’ 과제는 국립국어원의 ‘2022년 유사 문장 생성 말뭉치 연구 및 구축’ 사업을 통해 구축한 자료 중 표 기반 문장 생성 결과물을 활용하여 개발되었다. 이 자료는 해외 표 기반 문장 생성의 대표적인 데이터인 구글의 토토(ToTTo) 데이터 세트를 참조하였다. 데이터 세트는 에이치티엠엘(HTML)로 작성된 표의 형식을 유지하여 제이슨(JSON) 형식으로 변환되었고, 표에 음영으로 표시한 부분을 설명하는 문장 5개로 구성된다.
이 과제의 목표는 표에 음영으로 표시한 부분을 설명하는 문장 한 개를 생성하는 것이다.
분류 |
내용 |
예시 |
비고 |
입력 |
표 |
"input": { "metadata": { "title": "4차 산업혁명에 따른 조세환경 변화와 정책 과제", "table_title": "국제조세 과세원칙 일반 개념", "date": "2020-06-09", "publisher": "국회예산정책처", "url": https://www.nabo.go.kr/Sub/01Report/01_01_Board.jsp", "highlighted_cells": [ [ 0, 1 ], [ 1, 1 ], [ 2, 1 ] ] }, "table": [ { "value": "과세원칙", "is_header": true, "col": 0, "colspan": 1, "row": 0, "rowspan": 1 }, { "value": "특징", "is_header": true, "col": 1, "colspan": 1, "row": 0, "rowspan": 1 }, { "value": "이중과세 조정", "is_header": true, "col": 2, "colspan": 1, "row": 0, "rowspan": 1 }, { "value": "원천지국 과세", "is_header": false, "col": 0, "colspan": 1, "row": 1, "rowspan": 1 }, { "value": "소득이 발생한 국가(원천지국)에서 과세관할권 보유", "is_header": false, "col": 1, "colspan": 1, "row": 1, "rowspan": 1 }, { "value": "국외소득면제", "is_header": false, "col": 2, "colspan": 1, "row": 1, "rowspan": 1 }, { "value": "거주지국 과세", "is_header": false, "col": 0, "colspan": 1, "row": 2, "rowspan": 1 }, { "value": "거주자의 전세계 소득에 대해 거주지국에서 과세관할권 보유", "is_header": false, "col": 1, "colspan": 1, "row": 2, "rowspan": 1 }, { "value": "외국납부세액공제", "is_header": false, "col": 2, "colspan": 1, "row": 2, "rowspan": 1 } ] }
|
JSON |
출력 |
설명 문장 |
"output": "국제조세 과세원칙의 개념을 살펴보면 원천지국 과세는 소득 원천 국가에서 과세관할권을 보유하기 때문에 국외소득면제를 조정해야 한다." |
문자열 |
평가 |
ROUGE 1, ROUGE-L, BLEU |
|
|
구분 | 훈련 | 검증 | 평가 |
문장 수 | 7,170 | 896 | 896 |
평가 지표: ROUGE-1, ROUGE-L, BLEU
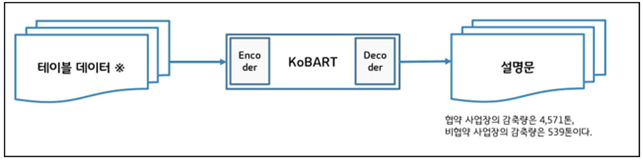
기준 모델(베이스라인 모델): KoBART 기반 학습 모델
- https://github.com/teddysum/korean_T2T_2023
대회 참가 규정
- 인공지능의 한국어 능력 평가에 관심 있는 누구나 팀을 구성하여 참가할 수 있다.
- 팀 구성원은 국립국어원 언어정보나눔터 회원이어야 한다.
- 참가 팀은 과제를 해결한 결과를 정해진 양식에 맞추어 제출한다.
- 라이선스에 문제가 없는 모델을 개발하여야 한다.
- 외부 API를 통해 호출하는 모델(OpenAI API 등)은 제출할 수 없다.
- 모두의 말뭉치를 포함한 외부에 공개된 데이터는 사용이 가능하다(저작권 등 책임은 참가 팀에게 있음). 과제 데이터(말뭉치)를 초거대언어모델(LLM) 기반 자동 증강하여 사용할 수 있다.
시스템 사용 방법: 알립니다 → 사용 안내 참고
문의: 진행 중 과제 → 문의
![]()
